Суть решения в том, что в пакетном запросе сначала заводится таблица с двумя строками, затем она соединяется сама с собой и число строк удваивается. Так повторяется до достижения таблицей заданного размера. Этот способ обеспечивает использование минимума соединений, от числа которых, в основном, зависит время выполнения запроса.
Для примера приведен запрос, формирующий таблицу из чуть более миллиона строк.

С его помощью можно сформировать таблицу значений в миллион строк примерно за 2 секунды, тогда как при использовании обычного метода последовательного добавления строк на это уйдет в два раза больше времени.
Для примера того, как можно использовать искусственные таблицы в запросах, приводится запрос, определяющий частоту символов в некотором тексте.
Текст и его длина передаются в запрос как параметры. Для примера считаем, что длина текста ограничена миллионом символов. Вот текст концовки этого запроса.

Его начало такое же как на предыдущем рисунке. Интересно то, что этот метод работает быстрее, чем обработка в оперативной памяти. И сразу дает табличный результат! Например, первый мегабайт романа "Война и мир" обрабатывается в памяти 8,2 сек, а запросом - 4 секунды!
Очевидно, что запрос совсем простой. Проявив некоторую изобретательность, можно построить запрос разбора текста на слова и запросы для решения других задач обработки текста. Аналогично можно строить таблицы вхождений одно, двух, трех и т.п. символов в наименования, артикулы и пр. для ускорения подбора (вместо методов с использованием "подобно").
В качестве неочевидного применения предложенного запроса приведу пример расчета в запросе квадратного корня от числа в диапазоне 0 - 1 048 576. Вернее, целой части этого корня.
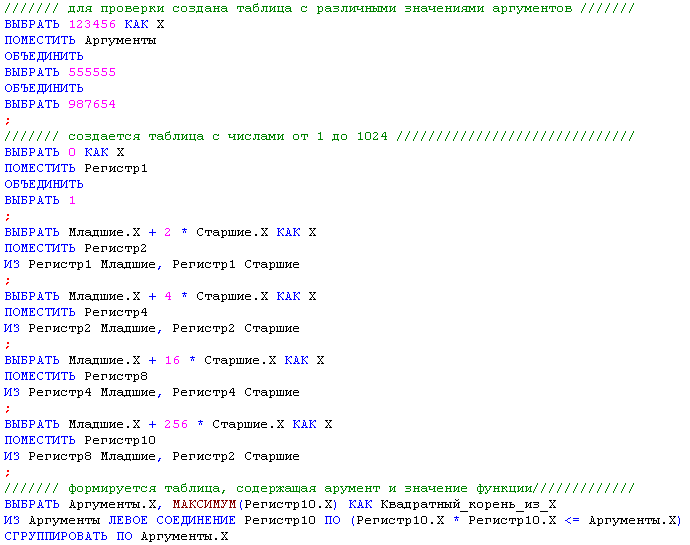
Аналогичным или похожим путем можно рассчитать и другие обратные функции.
необходимо зарегистрироваться для просмотра ссылки